
AI-анализатор финансовых новостей
Зачем он нужен
НовостнойАнализатор новостей помогает превращать обычный поток TokenBel содержит много шума: статьи о погоде, спорте, кино и бытовых темах, которые не имеют отношения к рынку ценных бумаг и токенов. Анализатор превращает этот потокстатей в чистые, структурированныепонятные финансовые события,события готовыеTokenBel. для новостного интерфейса.
СервисОн работает в фоне,фоне: безпользователь участияне пользователя.заполняет Какформу толькои не нажимает кнопки, а видит уже подготовленный результат в новостном разделе.
Задача анализатора — отделить финансово значимые материалы от шума, кратко объяснить событие, выделить связанные организации и инструменты, убрать дубли и сохранить аккуратную запись для дальнейшего просмотра.
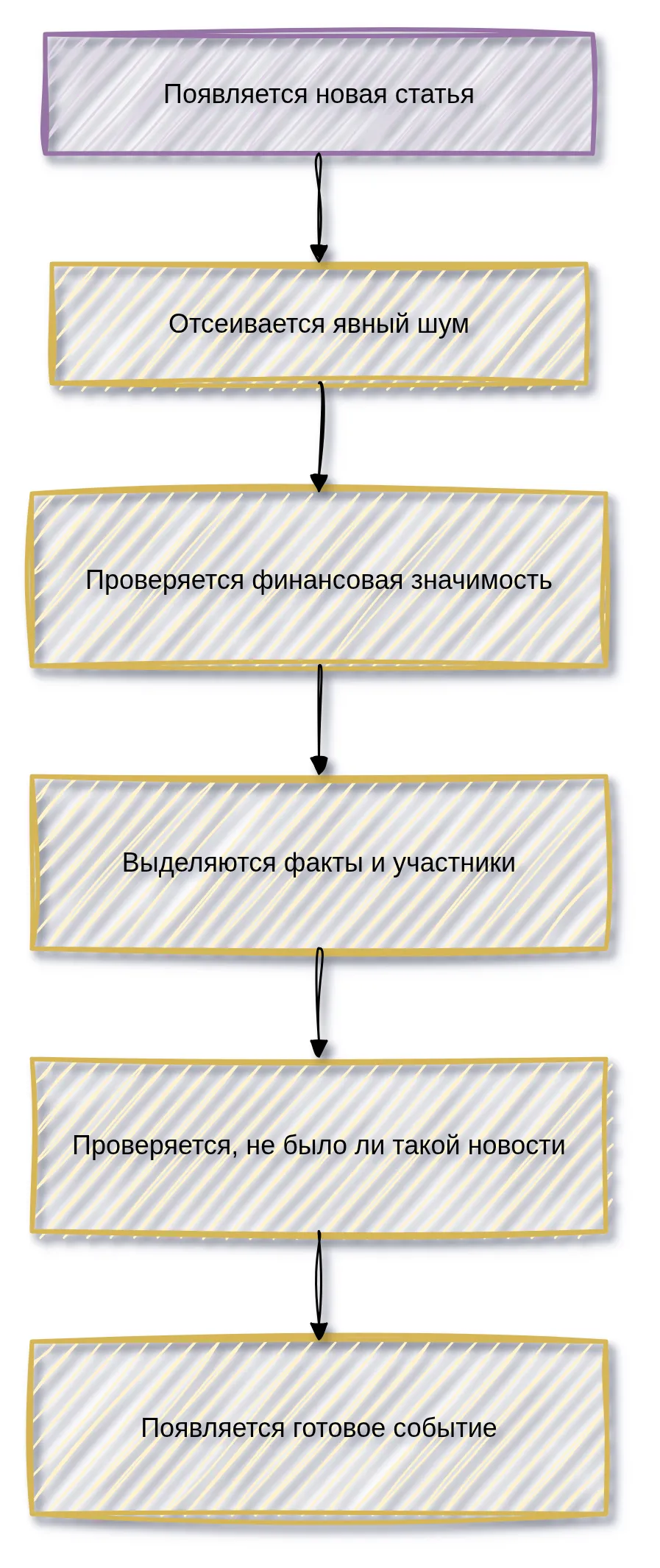
Место в новостном процессе
Анализатор включается после того, как новая статья сохраняется,уже он:найдена и сохранена как исходный материал. Он не ищет новости самостоятельно, а работает с теми статьями, которые поступили в новостной поток.
Для пользователя это означает простую цепочку:
отсеиваетсначаланерелевантныепоявляетсяматериалыисходнаяещё до обращения к модели;публикация;- затем система решает, относится ли она к тематике TokenBel;
Первичная очистка статьи
Перед смысловой проверкой статья приводится к более чистому виду. Из текста убираются лишние фрагменты, повторы, рекламные и навигационные вставки, пустые строки и другие элементы, которые мешают понять суть.
Этот этап нужен не для изменения смысла, а для того, чтобы дальнейшая проверка работала с содержанием статьи, а не с техническим или редакционным шумом вокруг неё.
Что может остановить обработку сразу
Статья может быть отброшена ещё до глубокого анализа, если она явно не годится для новостного события:
Отсутствие очевидных финансовых слов само по себе не останавливает обработку. Если статья может быть важной, но сформулирована неочевидно, она проходит дальше.
Проверка финансовой значимости
После первичной очистки система оценивает, подходит ли статья для TokenBel. Статья должна быть связана с инвестиционными или сберегательными инструментами, эмитентами, торговыми площадками, рынком, выплатами, регулированием или другими темами, которые помогают пользователю понимать финансовые события.
К глубокому разбору проходят материалы, где одновременно видно:
В основе смыслового разбора лежит языковая модель Mistral AI. Но модель подключается не сразу: сначала работают быстрые и дешёвые проверки, чтобы не тратить ресурсы на заведомо неподходящие тексты.
Где он находится в новостном процессе
Анализатор стоит между извлечением сырого текста статьи и появлением готового события в TokenBel. Он получает уведомление о новой сохранённой статье, забирает её полный текст из бэкенда, обрабатывает и записывает результат обратно.

Как система принимает решение
Решение проходит через несколько уровней — от самого дешёвого к самому дорогому:
Каждый уровень может остановить обработку. Благодаря этому полный анализ достаётся только тем статьям, которые действительно его заслуживают.
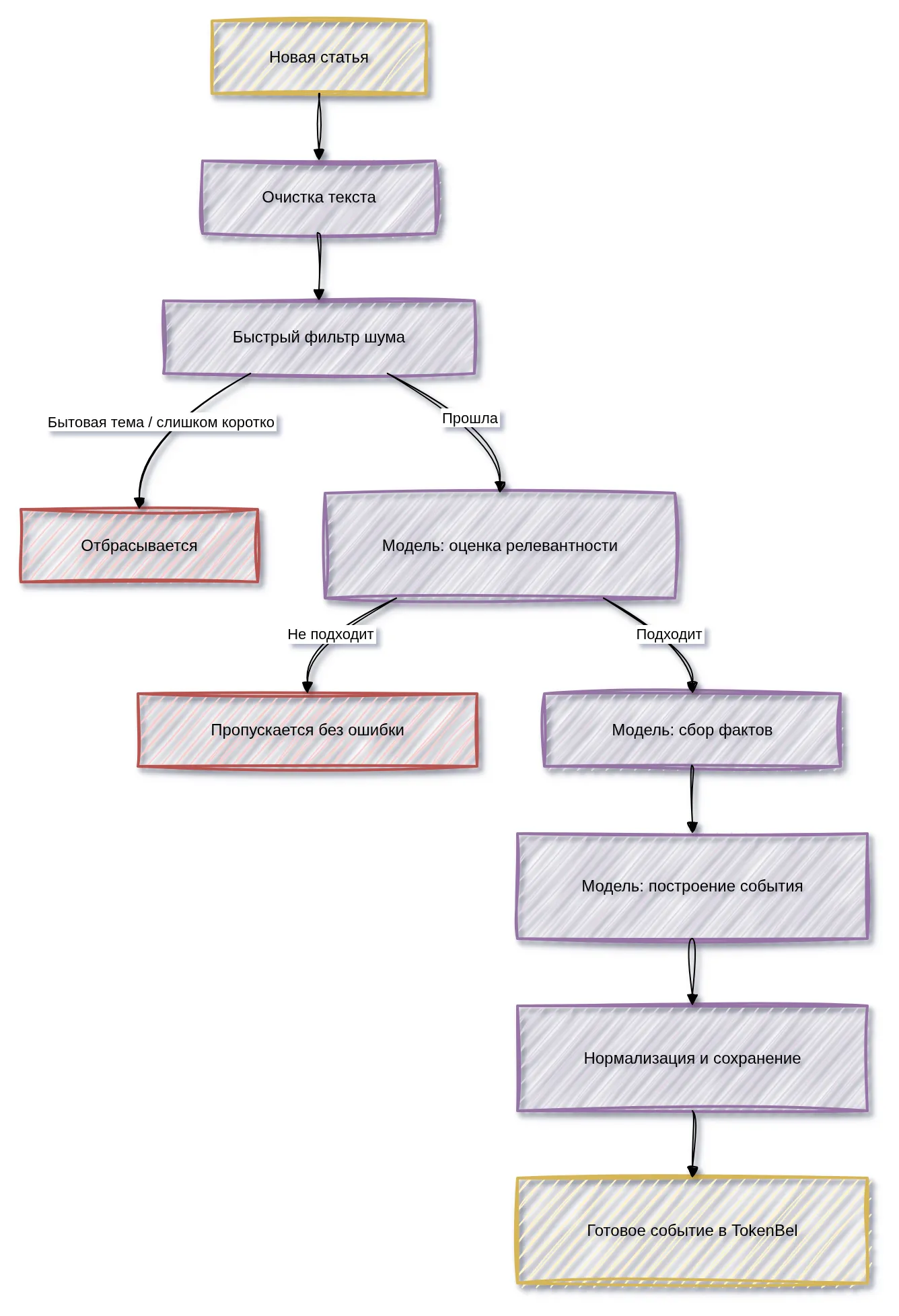
Этапы обработки статьи
1. Получение и проверка статьи
Система получает уведомление о новой статье и по её идентификатору забирает полный текст из бэкенда. Если текст пуст или сообщение битое, статья не уходит в обработку.
2. Очистка текста
Сырой текст приводится в порядок: удаляется технический мусор, лишняя разметка и пустые фрагменты. Длинные тексты укорачиваются до допустимого предела, чтобы не перегружать модель.
3. Быстрый фильтр шума
Перед обращением к модели система делает дешёвую проверку. Сразу отбрасываются:
Финансовые ключевые слова при этом не обязательны: если их нет, статья всё равно идёт дальше к модели. Фильтр намеренно мягкий, чтобы случайно не потерять важную новость с неочевидной формулировкой.
4. Оценка релевантности
Модель выступает в роли редактора-фильтра и отвечает на вопрос: «Стоит ли вообще разбирать эту статью?». Решение принимается по совокупности критериев. Если статья не проходит — она спокойно пропускается, без записи об ошибке.
5. Извлечение фактов
Для прошедшей статью модель отдельным проходом собирает «черновик»: факты, числовые значения, упомянутые объекты, возможные типы события и теги, а также замечания о неуверенности. Эти данные не показываются пользователю напрямую — они служат контекстом для финального шага.
6. Построение события
Финальный проход превращает собранные факты в готовое событие: короткий заголовок, суть в 1–2 предложениях, тип события, характер влияния, оценки важности и уверенности, теги, упомянутые сущности, ключевые факты и предупреждения.
7. Сохранение результата
Событие нормализуется (теги приводятся к единому виду, дубли убираются) и сохраняется в бэкенд вместе со служебным аудитом — записью о том, как модель принимала решения.
Что считается релевантной финансовой новостью
Чтобы статья пошла в глубокий анализ, оценка релевантности должна одновременно:
Тематические категории охватывают широкий спектр: акции, облигации, токены, эмиссии, новости эмитентов и компаний, корпоративные действия, выплаты, дефолт-риски, налоги, регулирование, рыночная инфраструктура, вклады, драгоценные металлы и валютный рынок.
Если хотя бы одно условиестатья не выполненопроходит —эту статьяпроверку, считается нерелевантной и пропускается. Это нормальный, не ошибочный исход.
Что сохраняется в результате
Для релевантной статьи в бэкенд записывается готовое событие новости:
Что происходит с нерелевантными или проблемными статьями
Поведение зависит от причины:
Какие темы считаются подходящими
К подходящим темам относятся не только акции, облигации и токены. Анализатор также учитывает:
ОсновнаяВажное логикаправило: простая:слово временным«токен» сбоямв системабелорусском даётинвестиционном второй шанс, а постоянные проблемы фиксирует, чтобы ониконтексте не застревалисчитается вкриптовалютой бесконечныхавтоматически. повторах.Если речь идёт о токенизированном инструменте, размещении, декларации или White paper, такая новость может быть релевантной для TokenBel.
Почему
Извлечение анализфактов
Для релевантной статьи система выделяет фактическую основу события. На этом этапе собираются:
Эти материалы не показываются пользователю как отдельная черновая карточка. Они помогают собрать более точное и осторожное итоговое событие.
Создание события
После выделения фактов формируется готовое новостное событие. Оно описывает не саму статью, а финансовый смысл того, что произошло.
В событие входят:
Текст события должен быть нейтральным: без советов, рекламных формулировок, эмоциональных оценок и выводов, которых нет в статье.
Проверка на несколько шаговдубликаты
НовостиПеред сохранением нового события система проверяет, не было ли уже очень похожей новости. Это важно, потому что один и тот же факт может появиться в нескольких источниках или повториться в близких формулировках.
Проверка учитывает не только заголовок. Сравниваются смысл новости, тип события, участники, даты, факты, значения и близость по времени.
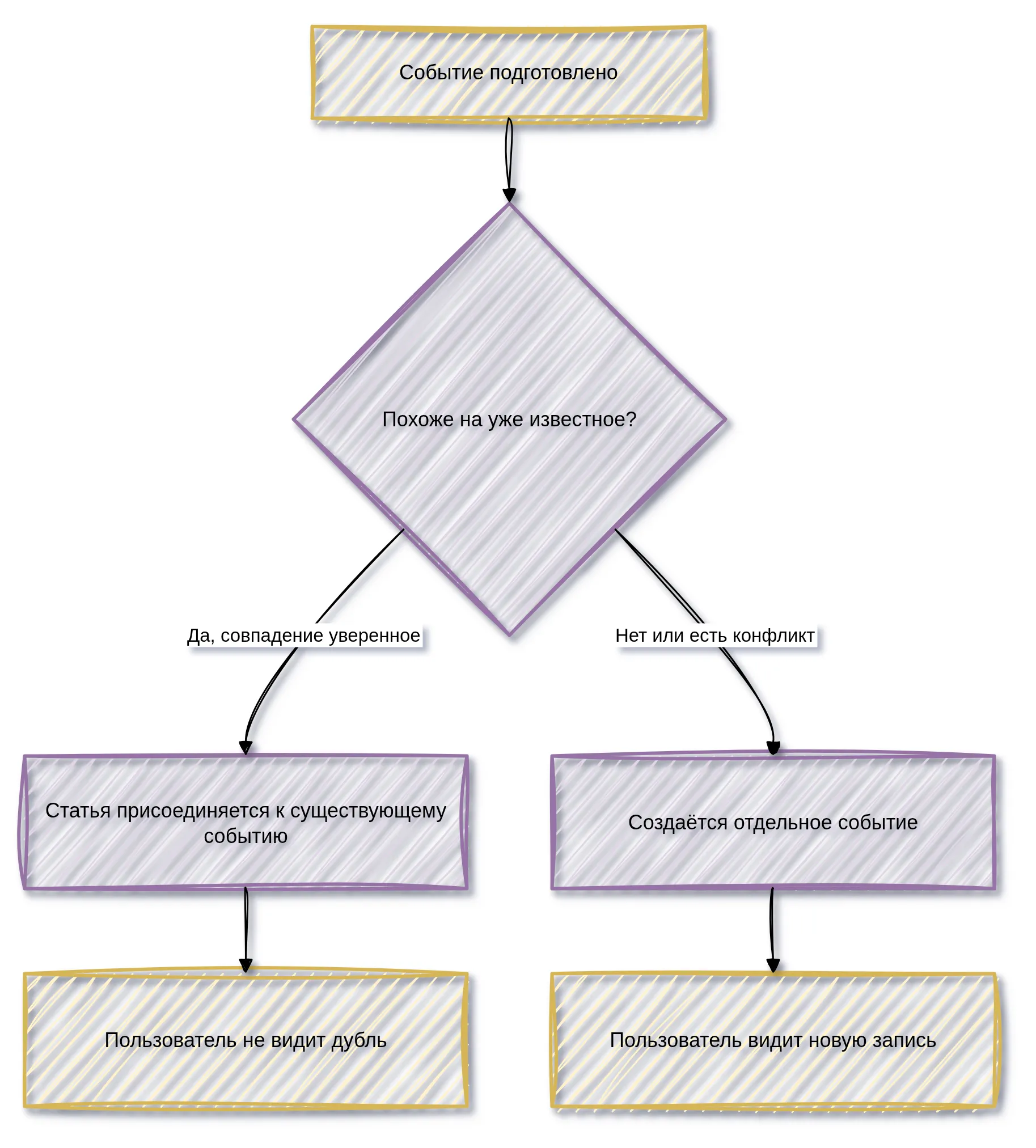
Если совпадение уверенное и не содержит противоречий, новая статья не создаёт дубль. Она связывается с уже существующим событием как дополнительный источник. Если совпадение слабое, спорное или конфликтное, система не объединяет новости автоматически и создаёт отдельное событие.
Редакторская вычитка
Когда событие не оказалось дублем, его текст проходит дополнительную редакторскую вычитку. Этот этап улучшает только читаемость: заголовок, описание, ключевые факты и предупреждения.
Структурные данные при этом не меняются. Тип события, характер влияния, оценки, теги и список упомянутых сущностей остаются теми, что были выбраны на этапе создания события. Это защищает результат от случайного изменения смысла при стилистической правке.
Что видит пользователь
Пользователь видит не весь внутренний путь статьи, а итоговую новостную запись. Она помогает быстро понять:
Если статья была только дополнительным источником к уже существующему событию, пользователь получает более чистый поток без лишних дублей.
Что происходит с неподходящими и проблемными статьями
Не каждая статья становится событием. Возможны разные исходы:
Главная идея: временным проблемам даётся повторная попытка, а нерелевантные или неисправимые случаи аккуратно завершаются.
Как связаны этапы
Каждый этап сужает поток и добавляет точность. Сначала убирается очевидный шум, затем проверяется смысловая релевантность, потом выделяются факты, создаётся событие, проверяются дубликаты и улучшается читаемость текста.

Такой порядок помогает не тратить глубокий анализ на неподходящие статьи и одновременно не терять короткие, но важные сообщения о токенах, выплатах, эмиссиях, вкладах, драгоценных металлах или валютном рынке.
Техническая схема слоёв
Внутри анализатор устроен как последовательность слоёв. Каждый слой получает результат предыдущего, делает только свою часть работы и передаёт дальше уже более структурированные данные. Это важно для управляемости: ранние слои дешёво убирают мусор, средние слои извлекают смысл, а поздние слои отвечают за дубликаты, читаемость и сохранение.
Слой не должен делать всё сразу. У каждого слоя есть свои «права»: что он может менять, где может остановить обработку и какие решения ему запрещено принимать.
На практике это даёт несколько защитных правил:
Поэтомук ранниеуже проверкисуществующему максимальнособытию;
Разделение на этапы делает систему одновременно дешёвой, быстрой и точной: дешёвые отсечения закрывают основной поток, а глубокий анализ достаётся только релевантным материалам.
Краткий глоссарий
- Сырая статья — исходный
текстновостнойновости,текст,сохранённыйкоторыйизвлекателемещёдонекакой-либопрошёлобработки.очистку и смысловой разбор. СобытиеНовостноеновостисобытие —структурированнаяготовая запись о финансовомсобытии:факте:заголовок,чтоописание,произошло,тип,свлияние,кемтегисвязано иупомянутыепочемусущности.
Техническая справка
Модель
Смысловой разбор ведёт языковая модель Mistral AI (mistral-small-latest). Запросы идут с temperature: 0 и жёстким форматом ответа json_object, чтобы ответы были стабильными и предсказуемыми. Если модель вернула невалидный JSON, делается одна повторная попытка с явным запросом «верни строгий JSON»; дальнейший брак уже не чинится.
Слои конвейера
Layer 0 — очистка (детерминированная, без модели). Сырой текст приводится в порядок: убирается технический мусор и пустые фрагменты, слишком длинные тексты укорачиваются до допустимого предела.
Layer 0.5 — быстрый фильтр (детерминированный, без модели). Жёстко отбрасывает заведомо нерелевантное:
Финансовые ключевые слова — негейтирующая подсказка: при их отсутствии статья всё равно идёт дальше к модели, чтобы фильтр не потерял важную новость с неочевидной формулировкой.
Layer 1 — оценка релевантности (модель). Решает, стоит ли разбирать статью. Чтобы пройти дальше, должны одновременно выполниться условия:
Layer 2.1 — извлечение фактов (модель, только аудит). Собирает факты, числовые значения, упомянутые объекты и замечания о неуверенности. Не задаёт финальные поля события — служит контекстом для следующего слоя.
Layer 2.2 — построение события (модель). Превращает факты в готовое событие: заголовок, описание, тип, характер влияния, оценки важности и уверенности, теги, упомянутые сущности, ключевые факты и предупреждения.